门店活动效果全维度分析项目
基于Python的门店营销活动全维度量化分析,自动化完成数据分层、统计检验、回归建模与业务报告输出
项目概述
本项目针对线下门店营销活动效果开展全维度量化分析,覆盖12个核心区域、1217家有效门店,通过Python实现数据分层建模、智能统计检验、多元回归分析全流程自动化,量化活动对不同维度门店的差异化影响,输出可落地的运营策略,解决活动效果评估与策略优化的核心业务问题。
项目背景
本次项目针对某产品线下门店活动效果开展全维度量化分析,核心目标是量化活动对不同区域、不同规模门店、不同开业类型门店的差异化影响,为后续活动策略优化、资源倾斜、区域精细化运营提供数据支撑。
分析覆盖12个核心区域、1217家有效门店,通过分层建模、智能统计检验、多元回归分析等手段,拆解活动效果的核心驱动因素,解决业务核心问题:
- 活动整体效果是否具备统计显著性?
- 不同区域/门店类型的活动效果存在哪些差异?
- 效果提升的核心归因是什么?
- 如何基于数据制定可落地的运营策略?
技术栈
| 技术/工具 | 核心用途 |
|---|---|
| Python | 项目开发核心语言 |
| Pandas / NumPy | 数据清洗、预处理、聚合计算 |
| Scipy / Pingouin | 正态性检验、方差齐性检验、ANOVA分析 |
| Statsmodels | 多元线性回归、模型诊断、稳健标准误修正 |
| Matplotlib / Seaborn | EDA探索性分析、可视化图表生成 |
| Openpyxl | Excel文件读写与结果批量导出 |
核心功能模块
1. 数据加载与预处理
- 支持Excel/CSV双格式数据自动读取
- 自动计算日均销量、活动增量(diff)核心指标
- 数据去重、缺失值清洗、无效门店自动剔除
- 全流程日志记录,保证数据可追溯
2. 门店智能分层建模
- 规模分层:基于累计实收自动划分小店/中店/大店
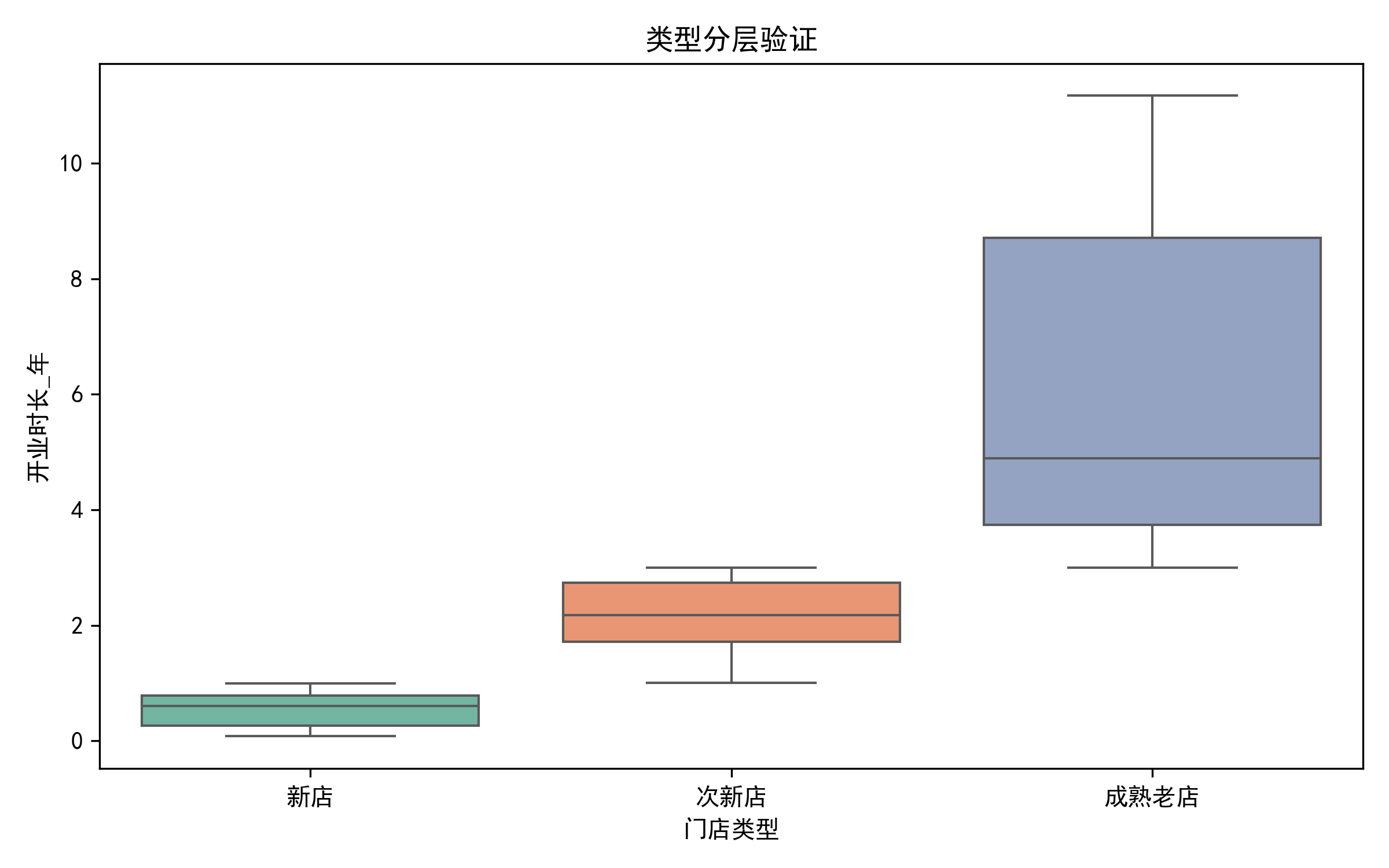
- 类型分层:基于开业时长自动划分新店/次新店/成熟老店
.png)
3. 多源数据自动匹配
- 活动数据+规模数据+类型数据一键合并
- 自动统计匹配率,输出数据清洗报告
- 保证分析样本的有效性与一致性
4. 探索性数据分析(EDA)
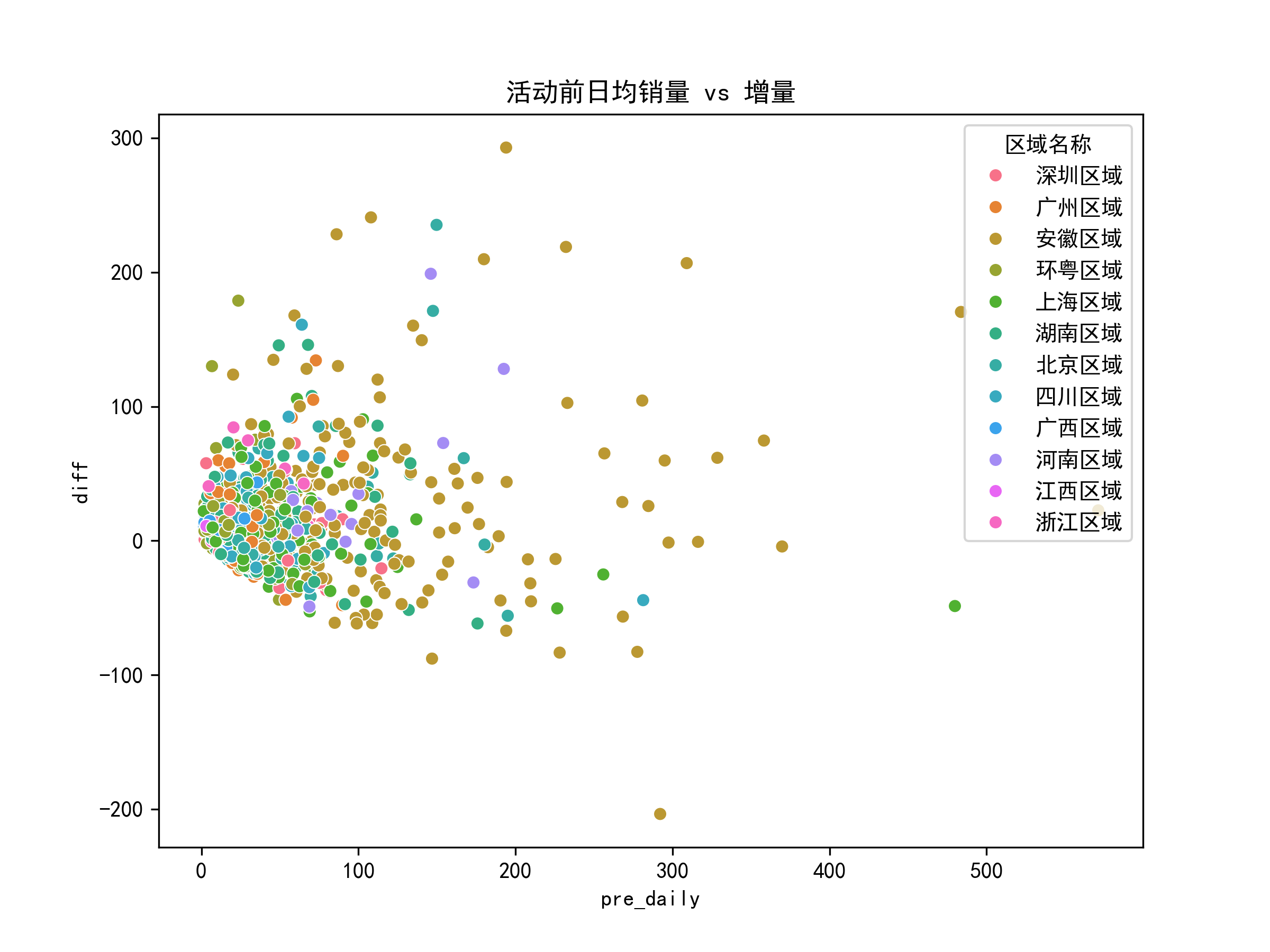
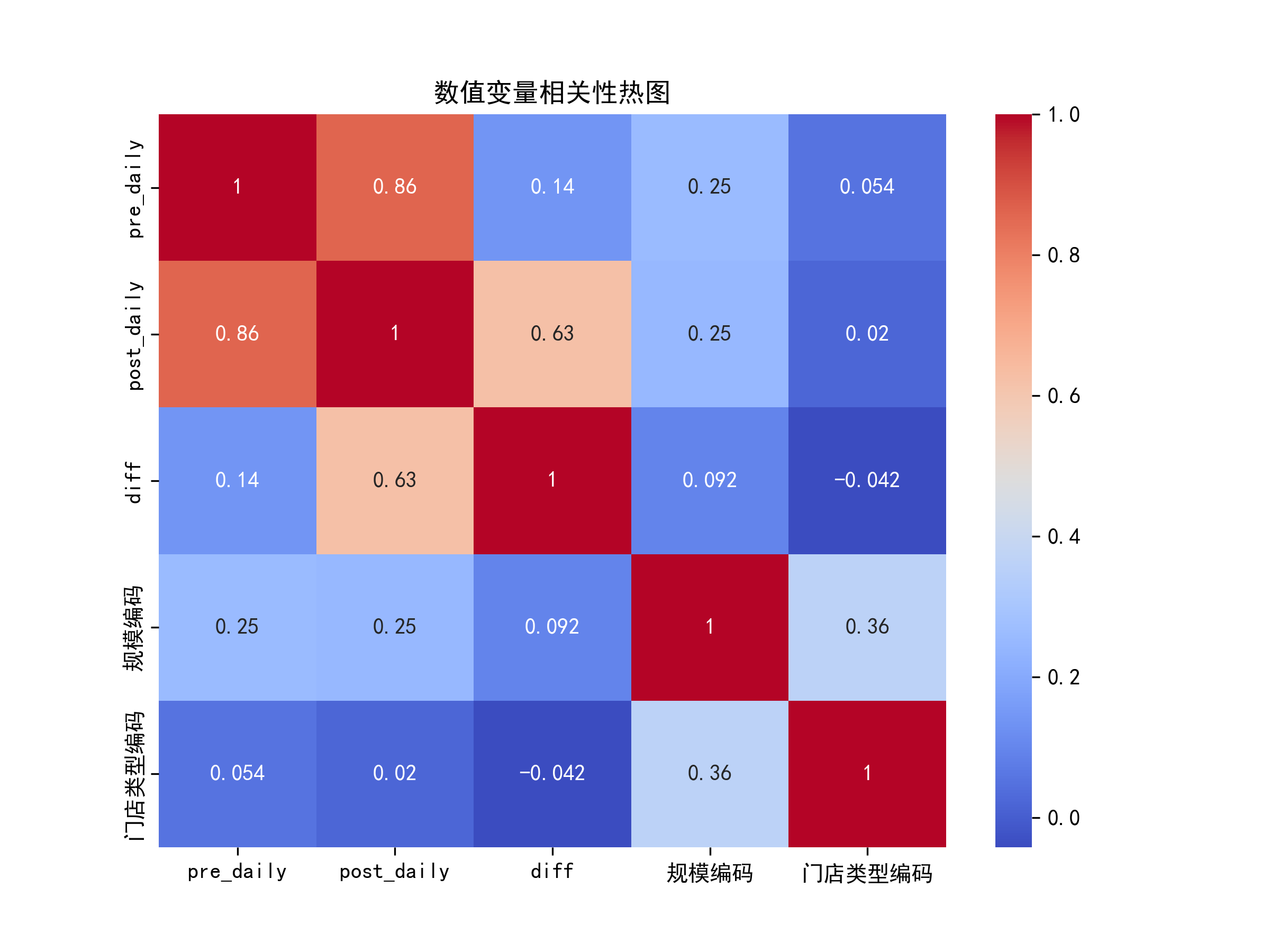
- 增量分布、区域差异、相关性热图可视化
- 方差齐性/正态性预检验,为建模提供依据
.png)
5. 高级统计建模(核心亮点)
- 三因素ANOVA:自动检验方差齐性,智能切换普通ANOVA/Welch ANOVA
- 多元线性回归:遵循层级原则,自动筛选主效应/交互效应
- 完整模型诊断:VIF共线性、残差正态性、独立性、方差齐性检验
6. 自动化报告输出
- 导出可视化图表+Excel量化结果
- 生成全维度汇总报告,对接业务决策
- 日志+结果双留存,支持全流程复现
核心分析结论
一、核心统计结论
- 活动整体效果显著:全门店活动后销量显著提升,回归模型具备统计显著性。
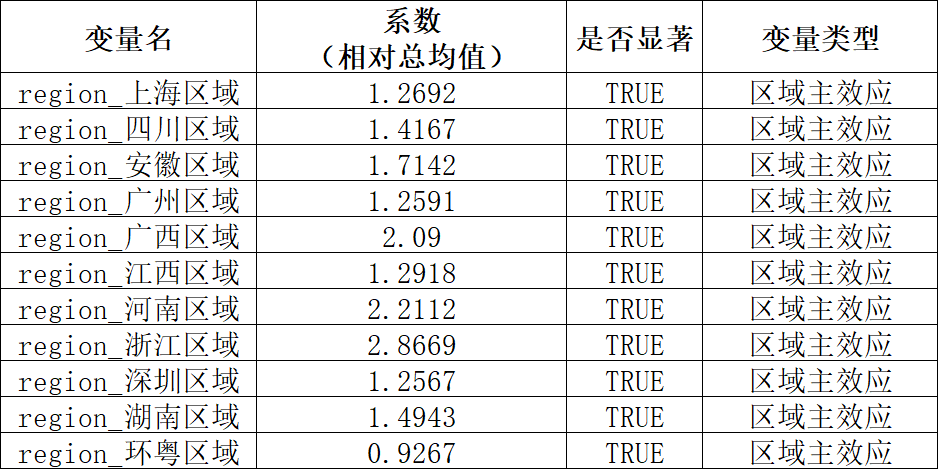
- 区域差异是核心驱动:区域名称解释9.16%的活动增量差异,属于中等效应。有大量其他因素(门店自身客流、活动执行、竞争环境)未被纳入考量。
- 门店规模/类型无显著影响:规模、类型对活动效果无统计学主效应。
- 模型拟合度:R²=0.16,区域+门店属性可解释16%的效果差异。经EDA相关性热图可知,活动前销量是重要预测因子,后续加入活动前销量提升R²。预计提升到0.6以上
二、区域活动建议(提升幅度从高到低)
- 加大投入:浙江、河南、安徽、广西,活动效果显著,可考虑延长活动时间、增加补贴力度,或作为新品首发区域。
- 诊断改进:环粤、深圳、广州。效果差,需排查原因:是否竞争激烈?门店执行是否到位?定价是否敏感?建议进行小范围活动测试。
- 重点关注:北京,p值边缘不显著,样本量较少,建议收集更多数据或单独分析北京门店的客群特征。
业务落地建议
- 资源倾斜策略:聚焦高效应区域,优化或收缩低效应区域。
- 策略简化:无需按门店规模/类型设计差异化活动,降低运营成本
- 区域优化:环粤区域开展活动形式、商品适配、执行力度专项整改
- 标杆复制:输出浙江区域标准化活动SOP,全国推广
- 长效监控:建立区域效果月度监控体系,持续迭代策略